How to become a data scientist, part 1: find a good problem
Posted on Thu 27 April 2017 in data science
Finding a good problem is the most important part of data science. You need: a good question or application, and good data.
- A good question or application.
For questions: Something you care about. I find curiosity is a good motivation. Something other people care about. Often you want actionable answers, i.e. where knowing the answer or using the application would lead someone to change their behavior. I lean towards bite-sized questions, so you can make progress within days or a couple weeks, and show others. After a few bites, they may head in a certain direction, and you can think about bigger questions.
For applications: Something that meets a clear business goal. Building something real, especially user-facing, will likely take sustained effort and support, it had better be worthwhile. Also, something fueled by data. - Good data. Well-defined: the important fields have a clear, consistent definition. Not too dirty: all data is dirty, but there has to be substantial useful information, too. I’ve usually gotten data where I work, very occasionally in combination with outside sources. Search, ask around. Or, there are many public data sources. Too many to list, but I list a few below.
- The common crawl - free, open-source web data often used for large language models (LLMs)
- Kaggle - datasets for machine learning contests (and more)
- U.S. census data
- NOAA weather data
the open U.S. government dataresources.data.gov - U.S. government data- usafacts.org - Steve Ballmer's site with U.S. statistics

If you have great questions or applications but no data, nothing happens. If you have datasets with no burning question or application, you might work hard, but not end up with anything useful. The second case is worse, because it takes longer to get out of, and digging around in data feels useful (but often is not).
Formulate a question before digging! In academia these are called “research questions”: high-level, easy-to-understand, important, motivating questions. Example: “How much does watering trees help them grow?” It doesn’t have details (like watering schedule, what kind of trees), but let’s you quickly evaluate and discuss with others if and why you might care. Ideally have one important question. Don’t have too many, that’s confusing.
Examples of good problems:
- Recommendations. A system to recommend books to read, movies to see, content (news, tweets, pins) to consume, clothes to try, restaurants to try. (Or try again. Re-recommendations are rare.) A classic example of actionable. Recommenders use data relating people to items. At Pinterest, we know what people pin to boards. You can try to bootstrap from someone else’s data if you can get it. No data, no recommender.
- Predicting important or interesting outcomes. Who is going to win the U.S. presidential election? For many people this may not be actionable, but is often intensely interesting. Predicting who wins a party’s primary is more actionable: you might not vote for someone who’s not going to win. Nate Silver of fivethirtyeight.com has proprietary methods, but they seem to use many polls, combined with prior beliefs about the political biases of the polls. I’ve talked to people who wanted to predict fantasy sports outcomes. Not my thing, but good for them.
- Opportunity sizing. Trying to understand whether an expensive opportunity (say, building a system or feature) is worth pursuing by estimating the benefit in understandable units (dollars, users).
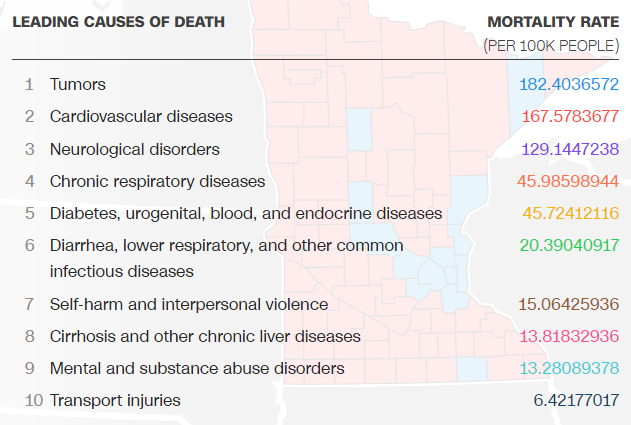
- Understanding the world. Want to know which television shows are correlated with geography (and likely politics)? How about the leading causes of death by U.S. county (see below)? Or the value of money accidentally destroyed in the U.K.? These are not directly actionable, but can shift your mental model of the world in useful ways. For example, if “self-harm and interpersonal violence” is more deadly than “transport injuries”, should we invest more in trying to lower it? How much do we invest? If you work for a business, you should form and constantly update your mental model for how the business works and why it is valuable to people. Call it “hypothesis generation”, i.e. ideas of how to improve (or not lose your special sauce!).
Trying to understand may generate more questions. As my friend Dmitry said:
“Ain’t no party like an analysts party because an analysts party keeps getting more questions to dive deeper into the analysis and it don’t stop.”
Knowing when to stop is an art. Decision-makers call this avoiding “analysis paralysis.” Amazon CEO Jeff Bezos from Amazon’s 2016 shareholder letter:
[M]ost decisions should probably be made with somewhere around 70% of the information you wish you had. If you wait for 90%, in most cases, you’re probably being slow. Plus, either way, you need to be good at quickly recognizing and correcting bad decisions. If you’re good at course correcting, being wrong may be less costly than you think, whereas being slow is going to be expensive for sure.
The complications
So that’s it. Seems pretty simple: pick an interesting question with some data. Reality is more complicated.
People don’t agree on what’s interesting. You need a sense of taste, or at least an idea of who to believe.
Some interesting questions don’t have data. The most common question without data that I face is: why? Why is this true? Why did this thing happen? Analyzing log data can tell you what happened, but not why. Controlled experiments (called “A/B testing” in the trade) can tell you what more definitively (yes, this button definitely makes people engage), but still not why. To get at why, you need to get in peoples’ heads. You can survey, i.e. ask questions of a crowd and use statistics to describe motivations. But you might get a deeper, more memorable understanding from qualitative methods like small group studies, interviews, or just talking to users.
Again, Jeff Bezos from Amazon’s 2005 shareholder letter:
Many of the important decisions we make at Amazon.com can be made with data. There is a right answer or a wrong answer, a better answer or a worse answer, and math tells us which is which. These are our favorite kinds of decisions.
…
As you would expect, however, not all of our important decisions can be made in this enviable, math-based way. Sometimes we have little or no historical data to guide us and proactive experimentation is impossible, impractical, or tantamount to a decision to proceed. Though data, analysis, and math play a role, the prime ingredient in these decisions is judgment.
Some interesting questions don’t have enough data. How are our users doing, given that we only have a few users? Say the business or feature is starting out, or starting out in a country or user segment. For example, startups right at the beginning often don’t need a data scientist, because there’s no data (unless their technology is based on data and they took pains to acquire some).
Some interesting questions are too hard. “You’re a smart fancy-pants, build me a predictive theory of everything, so I can just adjust the knobs and optimize my business.” Sadly, not likely. It’s easiest to be definitive about simple things, but the real world is complicated. “All models are wrong, but some are useful.” Usually, you just break off pieces and try to understand each piece. Only rarely do they get assembled into an accurate, quantitative, predictive whole.
Some interesting questions are unethical. I have been asked to support results I did not believe. I said no, and that had consequences. I have been offered jobs doing something I felt would make the world worse, maybe not terribly so. I did not take them. Data scientists are a force multiplier, accelerating the efforts of those around them. Do things you believe in. Sometimes (often), it is hard to decide whether something is good or evil. Is ride-sharing putting taxi drivers out of work, or offering people a flexible part-time job? Probably both. You have to use your gut.
All these possible complications can be surmounted. Think for a bit, discuss with potential users of your work, then choose. But think. If you choose the right problem, the result will have impact, meaning. If you choose the wrong one, there will be an uncertain period of discomfort and toil, followed by silence.
Previous: How to become a data scientist, part 0: introduction
Next: How to become a data scientist, part 2: try to solve the problem