How to become a data scientist, part 0: introduction
Posted on Fri 21 April 2017 in data science
I’m a data scientist at Pinterest. I have also worked with data at Amazon, Google, and a few startups. I get emails every week, sometimes every day, offering me jobs. I am grateful to them, and that my skills are valuable. There are jobs to share.
Recently, people have asked me how to become a data scientist, sometimes coming from very different fields. This is my advice about how to think about the profession and start acquiring the skills. I don’t comment on how to convince someone to hire you, or about data science boot camps.
All of this has been written elsewhere, too, probably better. I’ll sprinkle links.
Prerequisites: you can read, do arithmetic, use computers, look for things on the internet. Given those, you should
- Find a good problem.
- Try to solve it.
- Tell people about it.
Don’t wait until you’re qualified (whatever that is), jump in now.
The rest of this post talks more about what a data scientist is. If you’re not interested, skip ahead to part 1: find a good problem.
What is a data scientist?
The term “data scientist” is disputed. That is, since money, power, and people are involved, opinions vary.
First, my definition:
someone with computer skills to get and process lots of data,
statistical skills to make valid inferences that include estimates of uncertainty, and communication skills to explain the results to a less technical audience.
(Edit: Most often (but not always) “explain the results to a less technical audience” means “persuade someone to take action.”)
Although Wikipedia says the phrase has been around since 1960, Google Trends shows widespread interest is recent, starting around 2011:
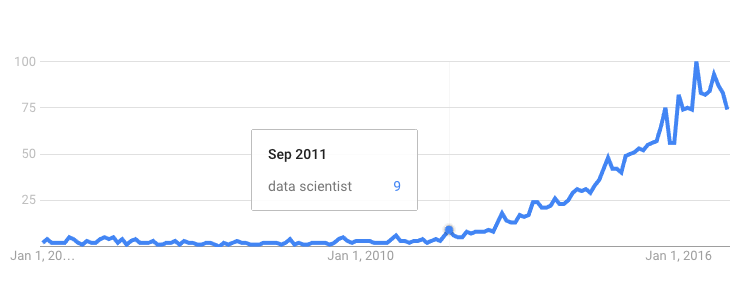
Nate Silver said, “I think data-scientist is a sexed up term for a statistician.” Many statisticians agree, and you may run across them decrying that old statistical methods have been rediscovered and renamed decades later.
However, many such methods weren’t practical before computers, especially in our data-rich era, so people who can really scale up data manipulation on computers have helped to usher in a new world.
Thus, computer scientists and Internet industry folk have put their stamp on the field. The joke goes, “A data scientist is a data analyst who lives in California.” The truth is, a large self-labeled “data science” community is in tech companies, mostly in California.
Josh Wills tweeted
Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.
He also said, “If you can’t tell whether a set of observations is i.i.d., you are not a data scientist.” That is intentional statistical jargon. He means understand the assumptions of your statistical tools. Not always easy:

My own quotable:
the difference between a software engineer and a data scientist is confidence intervals.
I also mean “understand and use statistical tools”, but focused on a problem I’ve seen often: software engineers who use numbers without considering uncertainty, due to lack of data or bad assumptions. Even if you have tons of data, answering a particular question might not use most of it. It seems a shame to make decisions based on random noise. More on that later.
Michael Hochster writes about type A (analytical) or type B (building) data scientists. Type A are “primarily concerned with making sense of data.” Type B “build models which interact with users, often serving recommendations.” This resonates with me. I’ve often been B, but lately mostly A. It depends on where I think I’ll add more value.
This post has a nice diagram of roles related to and near data science:
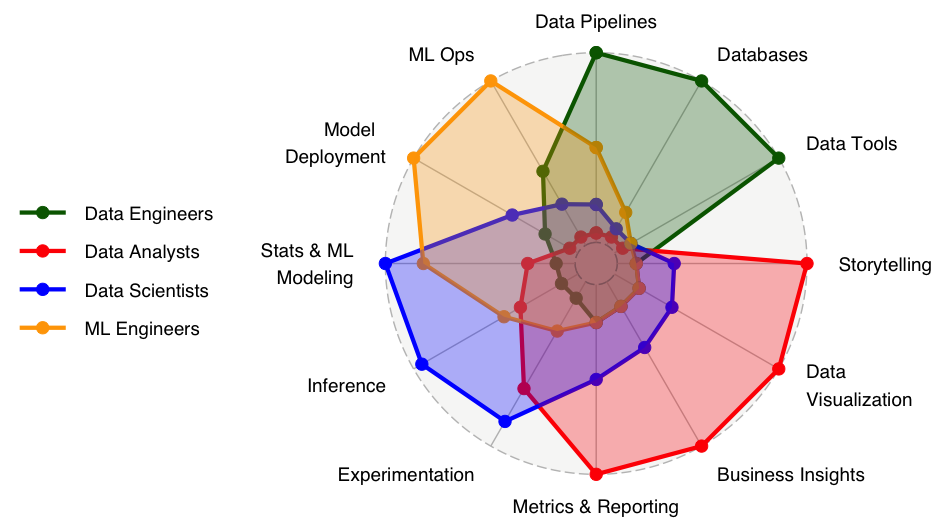
Related to this chart, I've been mostly talking about mostly the “Data Scientists” or “Data Analysts” role (often similar to “type A” analysis from above), but people sometimes use “data science” for the “ML Engineers” role (often similar to “type B” building).
It might be that the “Data Analysts” and “Data Scientists” tasks are closer to the type “A” (analysis), but it doesn't have to be that way. You can build tools for experimentation or reporting, though maybe this diagram would show that in “Data Tools” (i.e. the “Data Engineers” role).
If people call “Data Engineers” data science, they may not have much exposure to data science. Every field looks nuanced from the inside, and confusing from the outside. Data engineers are super valuable, but I would call them data engineers, not data scientists. I have done both, but I'm not as good at data engineering. It's a whole set of skills and (ever-changing) tools. This can be confusing, because “Data Tools” (engineering) can be aimed at any of the other axes (e.g., “Experimentation”), which will be best served by collaborations.
My own story (briefly): math major, computer science grad student, thought I’d be a mathematician, became a programmer, but spent a lot of time writing code to extract value from data, kept doing that until people started to call it data science.
I wouldn’t worry too much about exactly what the term means, just try to draw inferences or build models from data and see how it turns out.
A final note: I have found several statistical communities online to be prickly. If you don’t know something, you may be belittled (“instead of answering your question, I’m going to tell you to read a 300-page statistics textbook”). On the flip side, Cross-Validated has sometimes been helpful. There is also a data science stackexchange. I’ve never tried it. I should.
Next: How to become a data scientist, part 1: find a good problem